
 泰伯网企服小助手
泰伯网企服小助手随着自动驾驶迈向量产场景,“BEV感知+数据闭环”已成为新一代自动驾驶量产系统的核心架构。数据成为了至关重要的技术驱动力,发挥数据闭环的飞轮效应或将成为下半场从1到N的胜负关键。
觉非科技在此方面已进行了大量的研究工作,并在实际量产项目中开始了部分技术的应用。结合这些实践的经验,觉非科技感知算法专家戚玉涵博士近期在「生成式AI热潮下的自动驾驶」技术论坛中进行了分享,系统介绍了觉非科技“BEV感知+数据闭环”技术架构与研发进展。
一、觉非科技的数据闭环
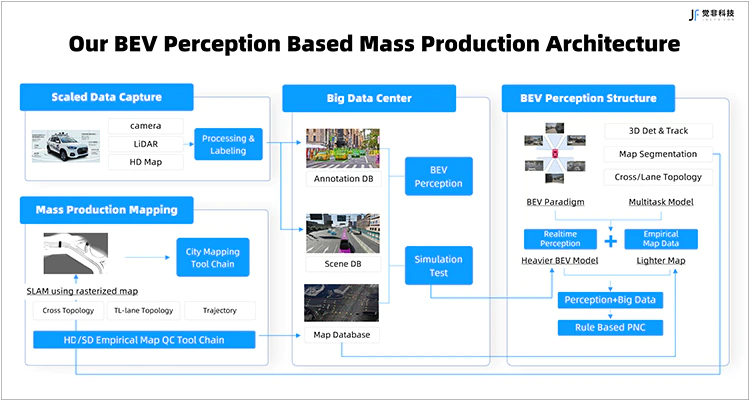
Fig.1 觉非基于BEV感知的量产架构图
觉非科技利用离线高精地图生成静态要素真值数据,用于训练基于BEV的静态要素感知模型;将模型部署于车端,实时推理时产生静态要素的栅格图结果并上传云端,在云端对栅格图进行SLAM拼接以及矢量化等后处理,通过量产化制图能力产生大规模的高精度地图数据库,进而实现静态要素的数据闭环。
觉非构建的大数据中心可实现快速不断的迭代,供给生成BEV感知算法的训练数据。觉非BEV感知任务包括三个部分:动态目标的3D检测与跟踪、静态要素的分割、以及静态要素的拓扑结构矢量图。
觉非的采集车配备7V相机(其中,采集车前向安装一台长焦相机,主要用于感知远距离目标),以及一台128线束的激光雷达。目前依赖点云检测来生成视觉BEV 3D动态目标感知的真值数据,其高度依赖于高精度的传感器标定和时空同步。
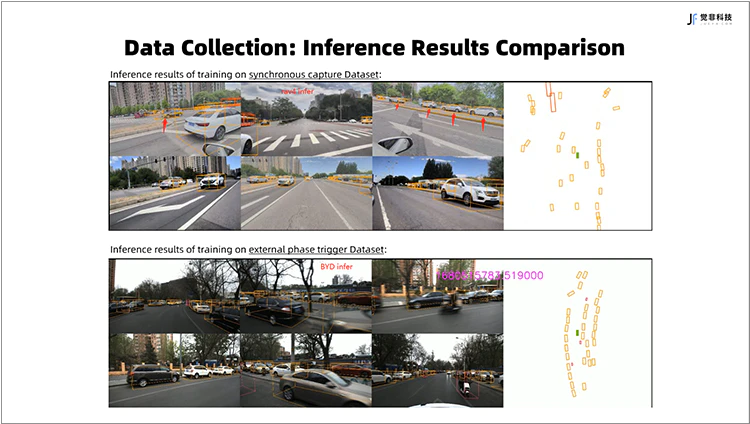
Fig.2 相机软件触发与硬件触发数采方式下,训练模型BEV 3D感知效果对比图
上图:相机软件触发方式采集训练数据的BEV 3D模型推理结果
下图:相机根据LiDAR相位角触发方式采集训练数据的BEV 3D模型推理结果
为此,觉非科技自研了基于高精地图的点云与相机的外参标定技术,同时依靠自研GNSS授时和根据LiDAR相位角硬件触发相机采集的同步板卡,对激光雷达和相机进行硬件同步,保证了BEV 动态目标3D感知结果的位置精度。
二、 觉非科技对BEV感知算法的优化方式
觉非BEV多任务联合感知算法的框架中,先将车周环视相机的图像接入BEV编码器,其结构包括backbone与neck,用于较好地提取图像特征;经视角变换模块得到稠密的BEV特征,与缓存的历史帧BEV特征一起送入时序融合模块,进行时序BEV特征聚合,时序融合能够提高被遮挡的动态目标的召回率,且提高视觉感知方式下目标速度的检测精度。
针对不同的感知任务,由BEV feature sampler设定不同的感知范围和BEV网格的粒度,对采样后的BEV特征进行解码和task head,得到最终动态目标3D检测和静态要素栅格图语义分割结果。
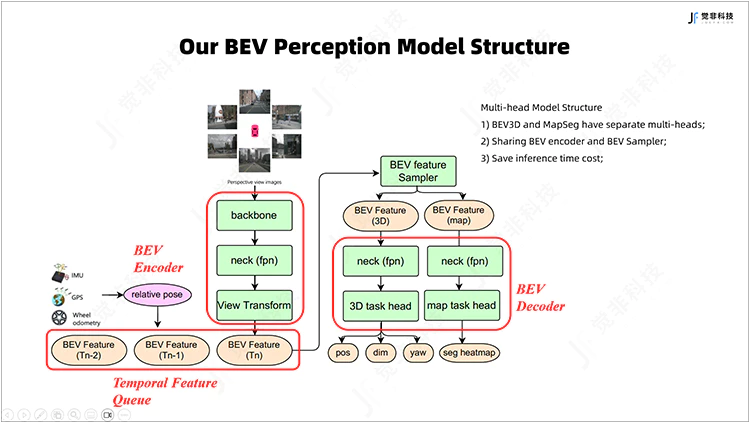
Fig.3 觉非BEV多任务联合感知模型框架图
在算法持续迭代的进程中,觉非的主要优化方向包含几个方面:
1. 视角转化(view transform)
目前学界在视角转换上存在很多范式,主流的方法主要包括LSS、MLP、Transformer
等。在考虑部署的便利性以及硬件平台对算子的支持等因素后,觉非选用的是LSS范式。
LSS范式下,视角变换模块利用depthnet网络输出两组信息,一是每一个像素点对应的图像上下文语义特征,其次是每个像素点上预测的深度分布,两路信息进行外积后可得出各个相机的视锥体(frustum)中每个像素点的上下文特征信息,从而实现2D到3D的提升。视角变换模块在工程化部署的方式上有两种方式:
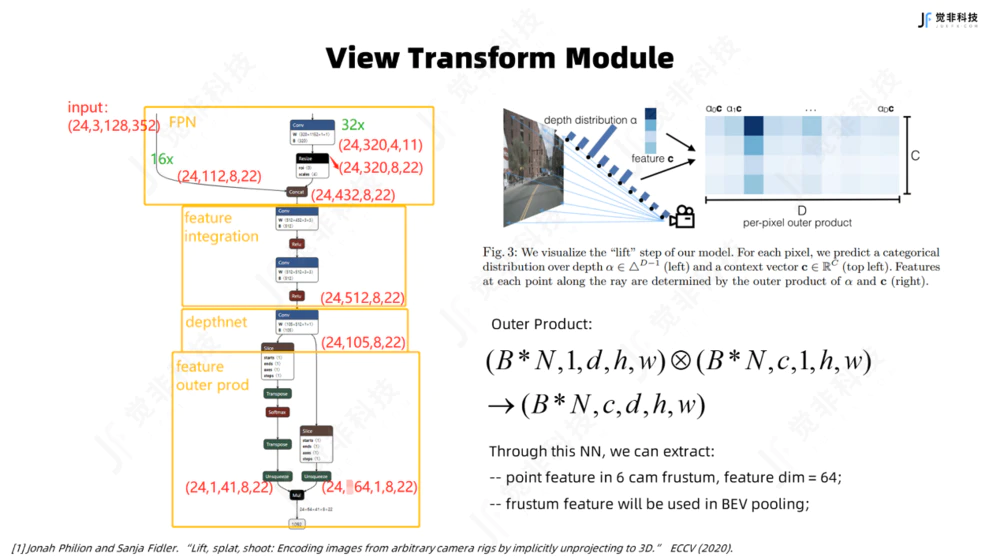
Fig.4 觉非视角转化模块
对于Nvidia的芯片,对每个像素点的上下文语义特征与估计得到的深度分布权重和进行外积实现Lifting,得到描述各个相机视锥体特征的到五维向量(B*N,c,d,h,w),而后根据相机参数将各个相机视锥体的特征splat到BEV视角下,可调用英伟达CUDA Kernal的多线程做并行加速来实现BEV的Pooling,得到聚合后的稠密BEV特征。
对于地平线J5芯片,根据车机视觉模组内外参数可预先计算出视锥体中每一个像素点与BEV网格唯一的哈希映射关系,而后在BEV网格进行特征聚合时,根据预设好的映射关系通过视锥体中像素点的索引值分别提取上下文特征和深度值进行相乘,所有BEV网格内的特征进行张量的求和,从而实现特征聚合。
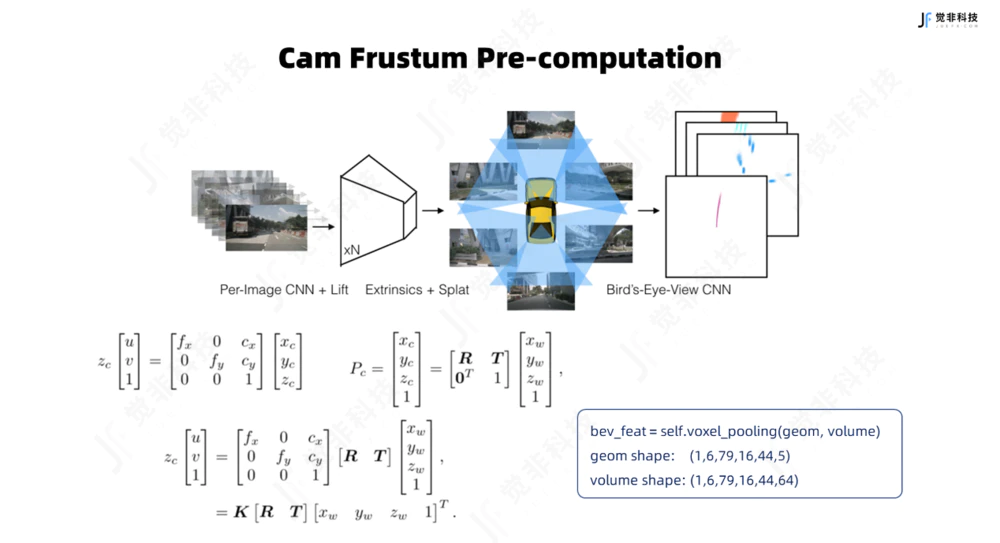
BEV pooling过程中的预先计算视锥点与BEV网格,可以在节约推理耗时,保证了模型在车端部署的实时性。例如,在实际落地实践中,觉非的BEV 3D感知可实现自车前后80米、左右40米范围,哈希映射计算前置与BEV pooling的并行加速节约耗时可达到16毫秒。
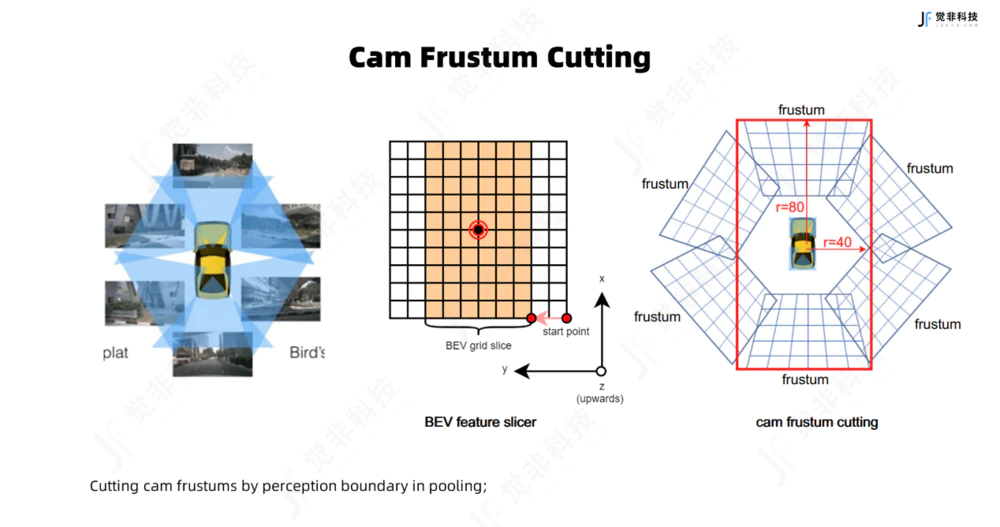
2.相机视椎体切割(Camera Frustum Cutting)
在BEV pooling环节中,可以根据预设的感知范围对参与BEV特征聚合的各个相机的视锥体进行裁剪,仅保留BEV感知范围内的视锥点参与特征聚合,可以节约参与BEV pooling的计算量。
3. 远距离感知(Long-distance Perception Range)
学界在BEV 3D感知上一般可实现车周半径51.2m(nuScenes数据集),或是75m(waymo数据集),而在真实的量产实践中,感知范围远远不能满足下游规划控制的需求。
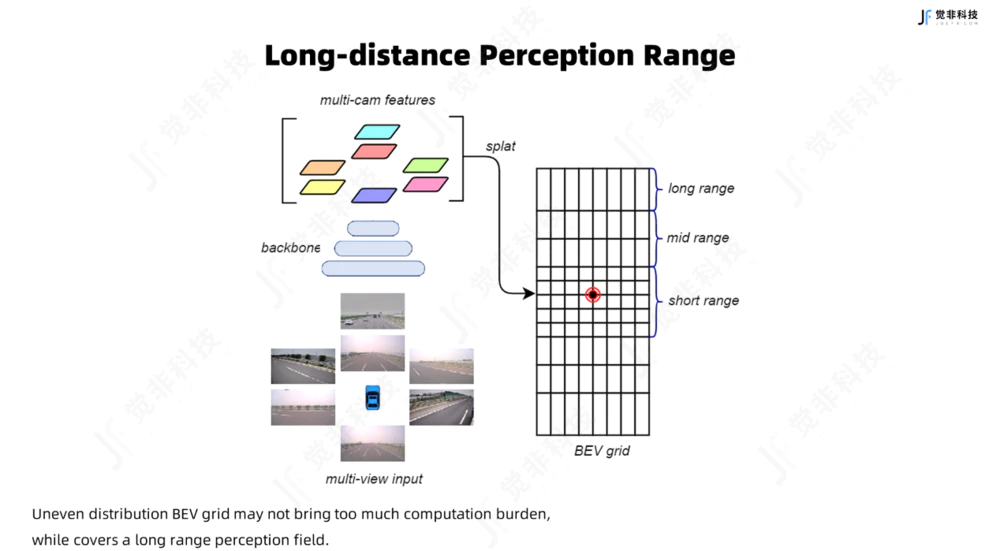
觉非科技的BEV感知方案中,除6v环视相机以外,在自车前视方向增加了1台长焦相机,可以感知远距离的目标;同时设计了一种非均匀粒度分布的BEV网格,在扩大BEV感知范围的同时,不额外增加过多的网格数量和模型计算量;同时引入点云数据对相机视锥点深度估计的显式监督,能保证模型对远距离动态目标的召回与较为精确的空间位置。
4.BEV坐标样本BEV Grid Sampler
觉非的BEV感知为多任务联合训练模型,感知任务包含对动态目标的3D检测与跟踪,静态要素的语义分割。其中静态要素的语义分割任务中,高分辨率的BEV特征是保证地面要素检测精度的前提。
因此在模型的设置上,觉非加入了BEV Grid Sampler模块,在对BEV特征解码前,该模块根据设定的地面要素感知的范围,对稠密BEV特征进行裁剪,并利用双线性差值方式对BEV特征上采样还原得到高精度、精细化的BEV特征。
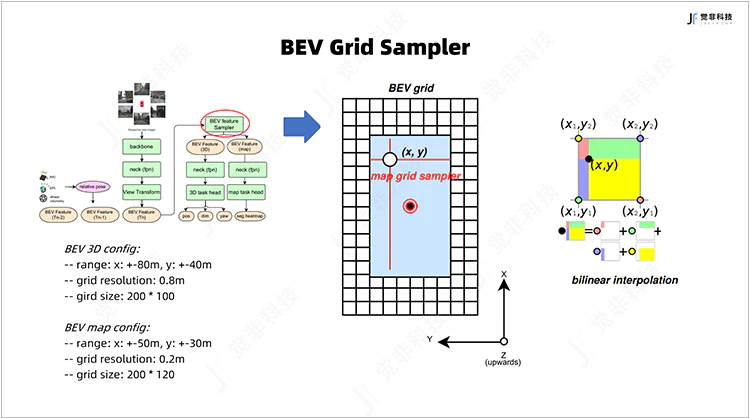
Fig.5 BEV网格采样器示意图
在联合训练的过程中,为避免同时训练不同任务对各个子任务性能的负面影响(一般称为:负迁移),觉非的联合训练模型中对不同的感知子任务设计了独立解码器,在解码过程中,各任务不共享BN(Batch Normalization)层的参数,可提升联合训练模型的稳定性并降低负迁移的影响。
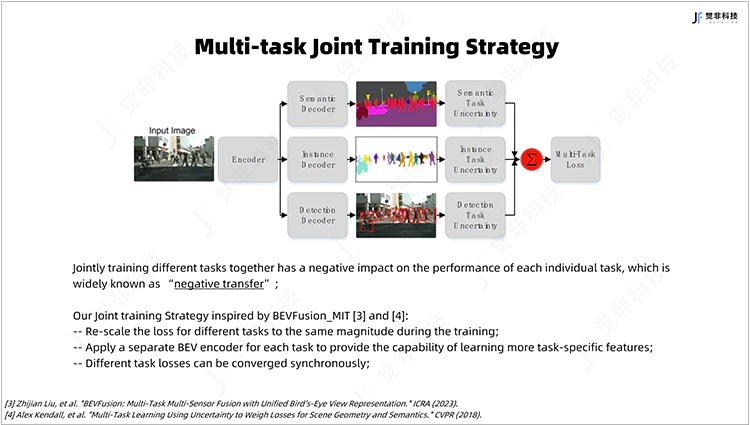
Fig.6 多任务联合训练策略
5.基于MapTR的创新与优化
在车端与路端大规模数据积累的基础上,觉非基于MapTR提出了相应创新优化,其中包括:
①对车道信息的表达方式进行优化,采用车道中心线进行表征并加入道路拓扑要素的建模;
②在不额外增加解码器query数量的基础上,通过回归车道宽度的方式还原车道标线的几何位置;
③学习车道线的虚实信息,可用于变道时判断旁边车道是否可以跨越;
④加入车道方向信息的学习,用于区分自车车道与对向车道;
⑤在MapTR的基础上加入了地图先验信息,有效提升模型输出地图元素的准确度与召回率。觉非对MapTR的创新能够系统化提升单车实时建图的能力,更易于自动驾驶规控使用。
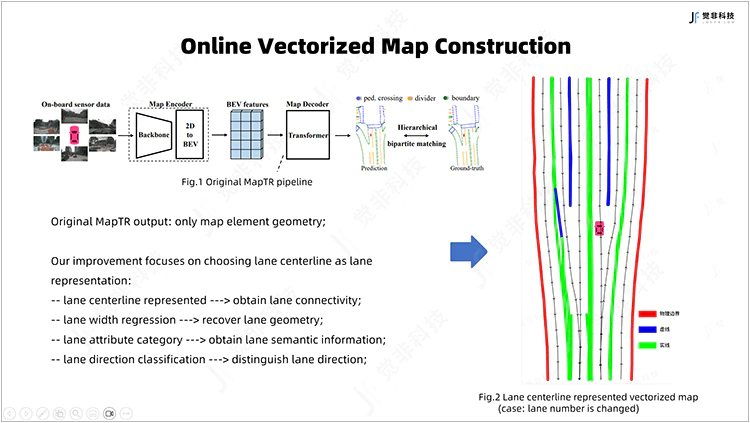
Fig.7 在线矢量化地图构建
目前觉非科技正在对“BEV感知+数据闭环”进行持续的优化,通过数据与算法的自研经验,以及在数据闭环搭建过程中大量的Know-How积累,为开发和迭代提供一套高效的工具链,并提升模型的泛化能力,在自动驾驶「数据驱动」的时代,推动数据闭环在量产车不断落地。












{{item.content}}